Introduction
In the fourth industrial revolution, the emerging role of artificial intelligence plays a vital role and makes substantial contributions to everyday existence. From Google assistant, Siri, Smartphone cameras, social media filters, automatic tagging, medical imaging, navigation and more — all of these are essentials in aiding and enhancing everyday activities.
Computer vision and image processing techniques are integral in capturing real-time images, extracting insights, and subsequently predicting and classifying these images autonomously, eliminating the need for human intervention.

Computer vision enables computers to interpret and detect patterns in the images, it’s primary aim is to replicate the human visual systems ability to process analyse and make sense of visual data. It can be further classified into four broader categories according to their use :
1. Object detection
2. Image classification
3. Semantic segmentation
4. Instance segmentation
Object detection
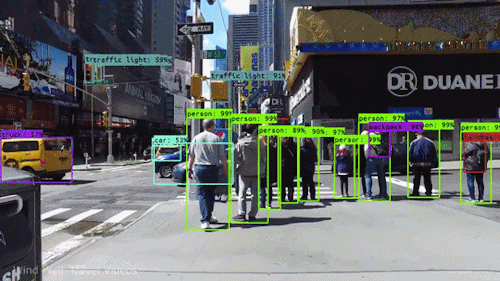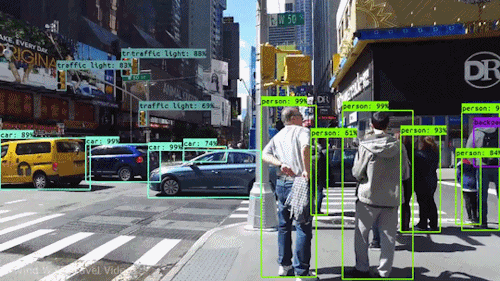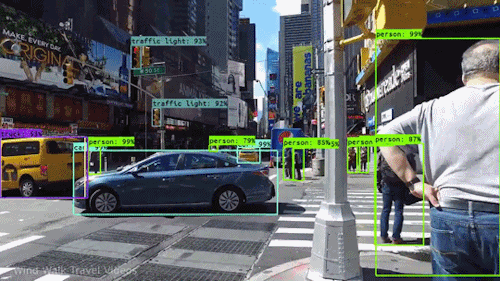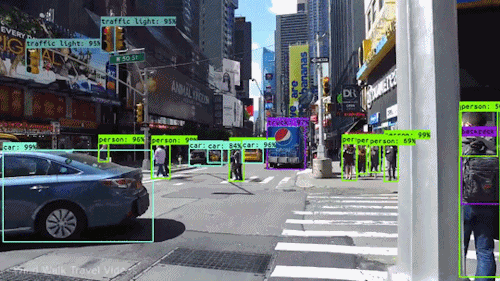
Object detection involves Detecting and localising objects of interest with an image or video. It uses bounding boxes around objects with their corresponding class labels, the goal is to precisely locate the objects and classify them accordingly. With the advent of deep learning models such as Region based Convolutional Neural Network (R-CNN), Faster R-CNN, You Only Look Once (YOLO) are being used for this task. Real world examples include autonomous vehicles to identify and track traffic science vehicles and obstacles in real life.

Image classification
The aim of image classification is to classify the images into one of several pre-defined categories. The goal is to make the Algorithm to recognise and assign correct label to the images based on its visual features and patterns it has several applications including medical images classification, Quality control, gesture recognition, hand written images classification. Deep Learning Architectures like Convolutional Neural network(CNN) and its types like LeNet, AlexNet, VGGNet, GoogLeNet (Inception), ResNet,DenseNet can be used to classify images accordingly.

Semantic Segmentation
Semantic segmentation uses pixel level classification that assigns label to each and every pixel that coordinates, partitioning the image into multiple segments, where each segment corresponds to a specific object class. This is particularly helpful in scenarios where the boundaries between different objects are not well defined where the precise location is required examples include brain tumour segmentation, autonomous driving ,satellite imagery and involves state of the art architectures including U-NET and DeepLab for this task.

Instant segmentation
Instant segmentation Is little more advanced and detailed version of semantic segmentation which involves categorizing objects within a class by means of assigning distinct labels within the same class. It provides pixel level differentiation between different instances of a same class It is also used in autonomous vehicles medical images etc

Other Techniques like panoptic segmentation,Optical Character Recognition,Image Captioning, Image Reconstruction are notable in this field. Integrating computer vision with other prominent fields of artificial intelligence paves the way for substantial advancements in the industry.

{kind=link}
{kind=link}